Read documents of Apache shardingsphere several years ago, and used to think it is the best database sharding library in client side. After trying to use it in a real-world application, problems reveal. First, the ecosystem has grown so large. Even a demo spring boot application can reference lots of dependencies. Second, when loading large data set from multiple shards, multi-threading is not used. I still have to manually implement it myself to improve load time.
Actually, what I need is the ability for selecting a database shard implicitly. When I write select t_user from..., it is rewritten to select t_user[0-7] from.... Here’s some alternative options I found:
See Techempower. This repository contains homemade java benchmarks using spring-mvc, spring-webflux and netty-http/netty-tcp servers based on reactor-netty. gin and gnet are also included. wrk is used as client. gobench is also considered but it is not so good as wrk.
2 VM Clients are not able to fully utilize the server capability. The initial attempts were benchmarking only first 4 cases. And the go-gnet results made me wonder, it can give much more throughput. After reading the source of it, I found go-gnet case is actually a TCP server with very very little of HTTP implementation to fulfill the benchmark, which is unfair for other cases. Therefore, I added case 5/6 in java to align with it.
Environment 2
Server: 24C32G physical machine
Client:
4C8G vm * 2
8C16G vm * 1
24C32G physical machine * 1
Server
Server Throughput
Server CPU
spring-mvc
~120k /s
~1560%
spring-webflux
~180k /s
~2380%
go-gin
~380k /s
~2350%
go-gnet
560k ~ 580k /s
~1160%
netty-http
560k ~ 580k /s
~2350%
netty-tcp
560k ~ 580k /s
~1460%
Still room to give more throughput in go-gnet and netty-tcp cases. Not having so many idle systems for benchmarking now. The throughput should have a linear increment when more CPU is utilized, in both cases.
As a developer, spring-mvc or go-gin can still be the first choice, as they are easier to get started.
Recently played with the Spring/SpringBoot/SpringCloud stack with a toy project: https://github.com/gonwan/spring-cloud-demo. Just paste README.md here, and any pull request is welcome:
Switch from Postgres to MySQL, and from Kafka to RabbitMQ.
Easier local debugging by switching off service discovery and remote config file lookup.
Kubernetes support.
Swagger Integration.
Spring Boot Admin Integration.
The project includes:
[eureka-server]: Service for service discovery. Registered services are shown on its web frontend, running at 8761 port.
[config-server]: Service for config file management. Config files can be accessed via: http://${config-server}:8888/${appname}/${profile}. Where ${appname} is spring.application.name and ${profile} is something like dev, prd or default.
[zipkin-server]: Service to aggregate distributed tracing data, working with spring-cloud-sleuth. It runs at 9411 port. All cross service requests, message bus delivery are traced by default.
[zuul-server]: Gateway service to route requests, running at 5555 port.
[authentication-service]: OAuth2 enabled authentication service running at 8901. Redis is used for token cache. JWT support is also included. Spring Cloud Security 2.0 saves a lot when building this kind of services.
[organization-service]: Application service holding organization information, running at 8085. It also acts as an OAuth2 client to authentication-service for authorization.
[license-service]: Application service holding license information, running at 8080. It also acts as an OAuth2 client to authentication-service for authorization.
[config]: Config files hosted to be accessed by config-server.
[docker]: Docker compose support.
[kubernetes]: Kubernetes support.
NOTE: The new OAuth2 support in Spring is actively being developed. All functions are merging into core Spring Security 5. As a result, current implementation is suppose to change. See:
Every response contains a correlation ID to help diagnose possible failures among service call. Run with curl -v to get it:
1
2
3
4
# curl -v ...
...
<sc-correlation-id:3265b50156556c05
...
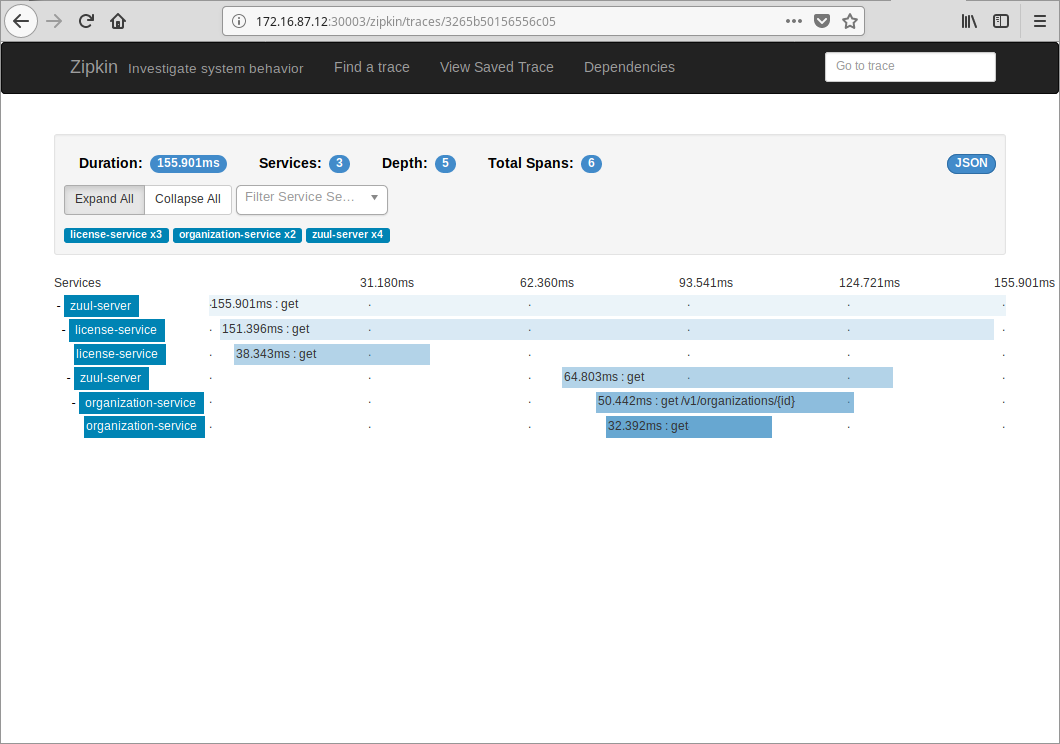
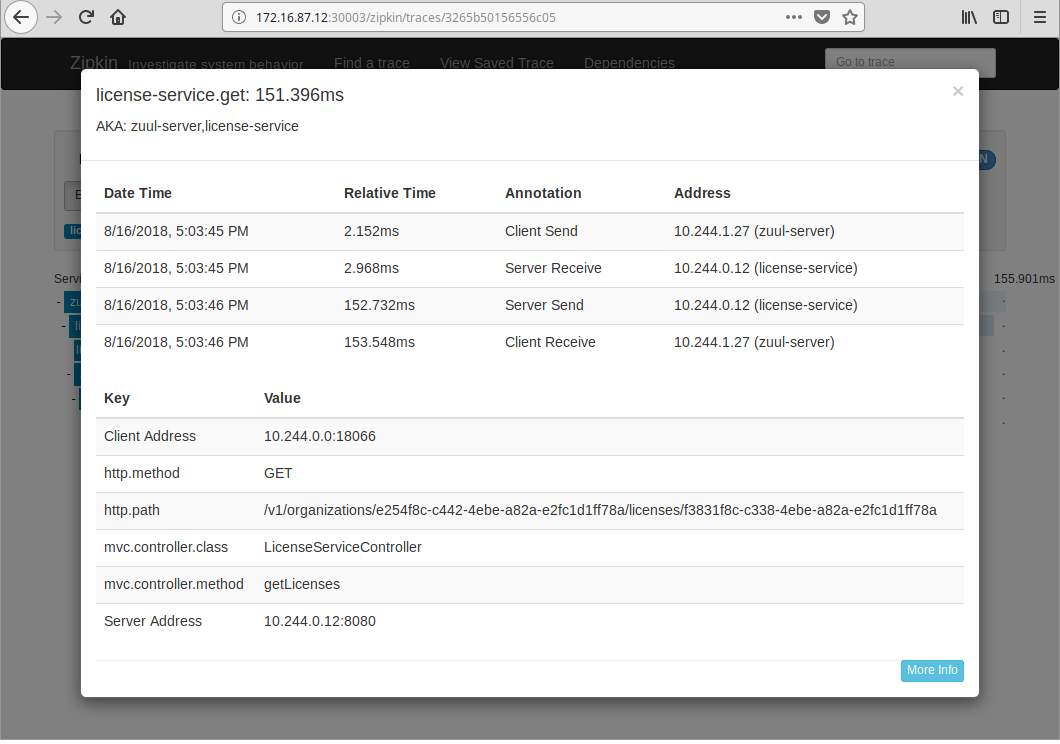
Search it in Zipkin to get all trace info, including latencies if you are interested in.
The license service caches organization info in Redis, prefixed with organizations:. So you may want to clear them to get a complete tracing of cross service invoke.
All OAuth2 tokens are cached in Redis, prefixed with oauth2:. There is also JWT token support. Comment/Uncomment @Configuration in AuthorizationServerConfiguration and JwtAuthorizationServerConfiguration classes to switch it on/off.
Swagger Integration
The organization service and license service have Swagger integration. Access via /swagger-ui.html.
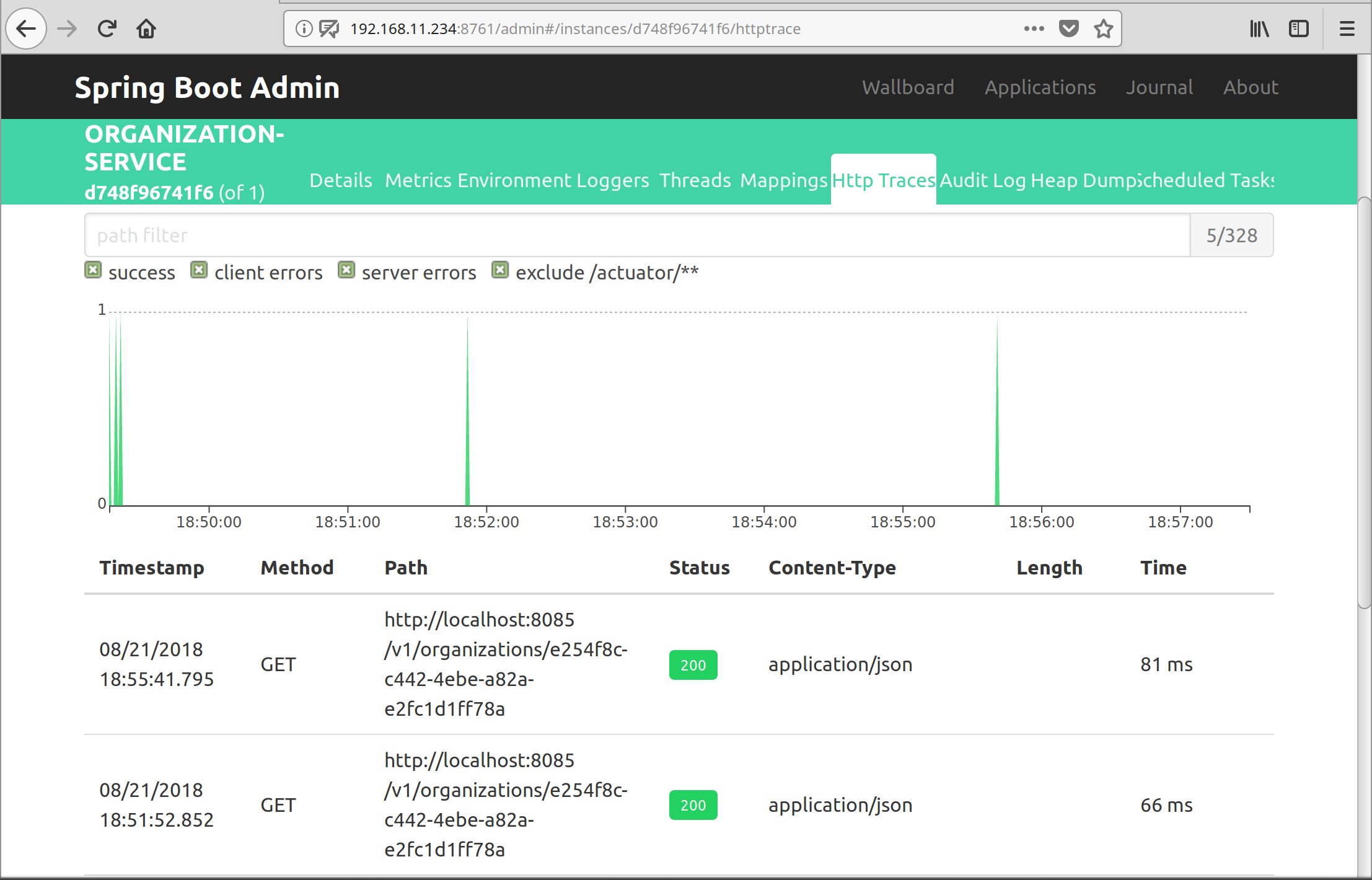
Spring Boot Admin Integration
Spring Boot Admin is integrated into the eureka server. Access via: http://${eureka-server}:8761/admin.